Автор: AxelS2002@mail.ru
Если начали читать этот текст, то возможно вы решили перевести некую игру скажем с английского на русский. В принципе нет разницы английский язык или любой другой европейский. Возможно, данное руководство не применимо если вас угораздило решиться на перевод с японского :-). В данном описании я рассмотрю подходы к переводу только однобайтовых кодировок. Что это за звери такие эти однобайтовые кодировки sbcs (Single Byte Character Set), надеюсь станет понятнее если у вас хватит терпения прочитать еще пару – тройку абзацев.
Для лабораторной работы нам понадобятся следующие инструменты:
- 1. шестнадцатиричный редактор (я буду приводить в пример GoldFinger)
- 2. Windows Commander для побайтного сравнения файлов и быстрого HEX просмотра
- 3. TileLayerPro утилита для поиска и редактирования битмэповых шрифтов в приставочных играх.
- 4. SnesTool для генерации IPS файлов (спец формат который позволяет выделить только измененные байты и надевать изменения на оригинальный образ ROM)
- 5. PokePerevod – утилита, смысл которой я постараюсь объяснить в ниже…
Глава Первая – В начале были буквы.
Если вам известно, чем кодовая страница отличается от шрифта, а печатные символы от непечатных, вам лучше продолжить чтение со следующей главы.
Начнем с простого, наверное вы читаете этот текст на PC 🙂 и соответственно объяснять, что такое IBM PC не надо (это было бы уж слишком для куловых хацкеров решивших ПЕРЕВОДИТЬ игры, а не просто мочить всех монстров до последнего патрона :-).
У персоналки (IBM PC) есть BIOS, в котором кроме всего прочего есть место где нарисованы шрифты, если посмотреть на экран пока машина грузится (русские Win9x нагляднее), то можно увидеть, что сначала выводимый на экран текст русскими буквами не читается, в смысле буквы мы видим, но они какие то не русские :-), потом весь русский тест видимый на экране внезапно становится понятным. Это значит, система загрузила MODE/DISPLAY/COUNTRY.sys которые в определенное место в памяти записывают новые ИЗОБРАЖЕНИЯ символов – шрифты :-). Ура с одним термином разобрались, идем дальше…
А когда мы располагаем, изображения символов в определенном порядке, на пример под номером 65 у нас нарисована заглавная английская буква “А”, под номером 66 будет нарисована буква “B” и так далее… значит мы придумали кодовую страницу (code page или character set). Причем обратите внимание, что программе глубоко наплевать что мы увидим на мониторе. Она просто говорит подсистеме ввода/вывода покажи на экране символы с кодами (hex) 66,55,43,4B :-), а что увидит пользователь программу никак не волнует.
Далее, производители персоналок договорились о СТАНДАРТНОЙ кодовой странице, которая состоит из 255 (или 256 🙂 символов и английские буквы там всегда имеют одинаковые коды, а остальные как захочет производитель :-)…
Поскольку вариантов нумерации изображений символов расплодилось много, то буржуины их пронумеровали и обозвали стандартными кодовыми страницами. Соответственно программа пишется с предположением, что на компьютере будет использована определенная кодовая страница и тогда он увидит на экране текст правильно…
Далее несколько констант (я буду пользоваться этими названиями ниже):
Для русских символов существует несколько СТАНДАРТНЫХ кодовых страниц (мы же блин не американы какие то, нас умом не понять 🙂
- MS DOS codepage – “cp866”
- MS Windows – “Windows-1251”
- Unix – “ISO8859-5”
- Mainframe – “cp1025”
Есть еще одна кодовая страница проталкиваемая основоположниками FIDO в России под названием KOI8-R (ее использование, впрочем не лишено определенного смысла…)
Есть или вернее было еще несколько кодовых страниц на ПК типа Искра1030, Роботрон и т.д. о них читайте в учебниках истории развития компьютеров.
Как вы наверно догадываетесь текст написанный в одной кодировке не читается при использовании другой кодовой страницы (объяснять не буду, если не понятно почитайте спец. литературу для супер-чайников).
Однобайтовая кодировка (кодовая страница) – это когда одному байту соответствует один символ и получается, что всего символов закодированных таким образом может быть 255 (или 256 :-). Бывают еще двухбайтовые кодировки (double byte character set), когда одному изображению символа соответствует два байта и соответственно в кодировке может использоваться 65536 символов. Ярким представителем такой кодировки является Unicode. А есть еще смешанные кодировки (multi byte character set) типа UTF-8 когда английские буквы кодируются одним байтом, а все остальные символы двумя…
Далее речь пойдет ТОЛЬКО об однобайтовых кодировках.
Глава 2 – Особенности перевода приставочных игр.
Рассмотрим вариант, когда программа работает не персоналке, а на приставке типа GameBoy. Дело в том, что у GB своего BIOS’a нет (в том понимании как это есть у IBM PC), поэтому вся программа (включая подсистему ввода вывода находится в так называемом ROM картридже). И соответственно, имея образ этого картриджа можно поправить как шрифты, так и текст игры. Вообще поправить можно все, что угодно, но мы с вами говорим о переводе а не о ломании игр. Разница между PC и GB лишь в том, что там нет понятия стандартная кодовая страница (кодировка). Каждый производитель игр может сочинить свой charset (кодировку) где, на пример коду 0x00 будет соответствовать изображение английской буквы “A” и сообственно сложность при переводе приставочных игр заключается в том, чтобы догадаться какими кодами кодируются символы выводимые на экран.
Далее задача раскладывается на четыре:
- 1. найти шрифты (изображения символов)
- 2. написать таблицу соответствия символов (вычислить charset).
- 3. дорисовать недостающие изображения символов (русские буквы)
- 4. перевести текстовые строки в игре на другой язык.
Опыты над разными образами игр (для GB) показали, что в случае если игра выпущена для европейских языков (английский и т.д.) то там как правило есть место для 255 символов, но изображения как правило есть только для тех букв, которые выводятся на экран, а изображения других букв кодировки просто оставлены пустыми.
Во многих руководствах и мини туториалах по переводу приставочных игр говорится о ЗАМЕНЕ изображений английских символов русскими и последующем переводе. Однако такой подход приводит к тому, что тот текст который еще НЕ переведен не читаем (вспомните работу русского scandisk при загрузке Win9x) и соответственно у игрока нет никаких шансов догадаться о том, что там ему говорят… Это не дает возможности нормально играть в частично переведенную игру. Поэтому далее я постараюсь объяснить, как можно переводить и оставлять понятным, то, что еще не переведено.
Глава 3 – Перевод в лоб.
Вернемся к нашим баранам. Сначала попробуем разобраться с двоичными файлами (играми) на PC.
Далее если не указано специально речь идет о программах работающих под M$Windows и соответственно, кириллица в кодовой странице Windows-1251.
Рассмотрим какую нибудь программу в двоичном виде. Картина будет примерно следующая:
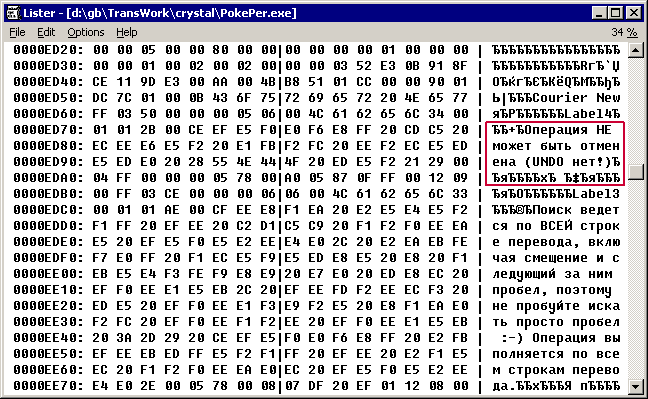
То, что мы видим в левой части экрана это коды символов в HEX виде, то, что в правой части – это изображения символов. Соответственно верить можно только левой части, а правая зависит от разных настроек системы. Причем обратите внимание, что мы разглядывая таким образом программу, видим и исполняемый код и текстовые константы. Если вы не знаете, что такое исполняемый(двоичный) код, читайте спец. литературу… 🙂
Соответственно, что мы делаем, если хотим перевести этот текст на другой язык. Мы своим зорким глазом отличаем печатные символы от непечатных, (тех что на экране обычно не встретишь). И далее вставляем в левую часть другие коды, которые соответствуют другим печатным символам, и соответственно с правой стороны, увидим скажем английские буквы.
Следует заметить, что если в результате наших изменений мы вдруг забьем несколько позиций “непечатных” символов, то программа может перестать работать (это запросто могут оказаться исполняемые инструкции). С другой стороны часть непечатных символов (с нашей точки зрения) может быть вполне печатными (на пример немецкие умляуты).
Если вы увидите картину типа такой:
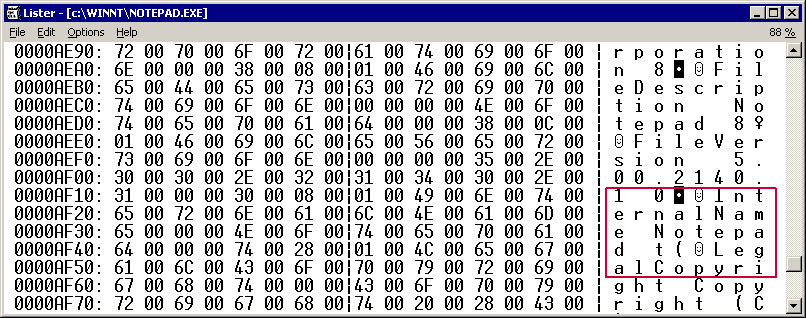
…то вам не повезло, тут используется двухбайтовая кодировка, и перевод такой игры может сильно усложнится не потому, что тяжело работать с Unicod’ом, а просто мало утилит нормально с ним работают и это значит инструментарий переводчика придется писать самим :-).
Для того, чтобы уже, наконец закрыть вопрос “лобового перевода” следует заметить, что набить в HEX редакторе даже 20-30 килобайт текста под силу только самоотверженным людям 🙂 а за набивание более 100Kb можно просто памятник ставить (посмертно, поскольку процесс перевода может длиться всю оставшуюся жизнь 🙂
Глава 4 – Волшебные поинтеры и с чем их едят.
Идея достаточно проста – как бы вынуть весь текст из файла, перевести его, а потом засунуть обратно в те же места…
Если приглядеться к тому, как переводят в лоб, то можно заметить, что:
- 1. глазами находят текст и запоминают смещение, где это текст лежит в файле
- 2. вычисляют, где этот текст оканчивается (каким нибудь непечатным символом типа 0x00)
- 3. подбирают перевод фразы сходный по длине с оригинальной строкой
- 4. набивают его в те же места.
Данный процесс вполне поддается описанию, скажем на Visual Basic’e, главный вопрос в том, как программно отличить печатные символы от непечатных. Тут нам на помощь приходят все те же таблицы символов (codepages). Однако в СВОИХ таблицах мы опишем коды ТОЛЬКО печатных символов. Теперь программа может отличить коды печатных символов от непечатных и все, что остается это разобраться в том, как отличить текстовую строку в файле от двоичных инструкций. Для этого опять вернемся в лобовому переводу – там мы глазами читаем весь файл по байтику, пока не встретим последовательность печатных символов. Ура ключевое слово произнесено (кто не догадался я не виноват, в качестве эксперимента могу вам прочитать двоичный образ скажем Winword.exe и найти там текст, думаю к концу чтения все станет понятно 🙂
Далее все (или почти все) делает железяка – сканирует файл и вынимает ВСЕ последовательности печатных символов (тех, что есть в таблице, остальные считает непечатными) если встречает 2 или более печатных символа подряд, то такая последовательность записывается в файл отчета (на пример report.txt)
Структура выходного файла может быть проста до безобразия:
десятичное_смещение_в_двоичном_файле+пробел+последовательность_символов+crlf (признак конца строки)
Следует заметить, что если мы говорим о том, что переводиться будет приставочная игра, со своей кодировкой, то нам такой выходной файл ничего не даст, на персоналке в нашей windows-1251 мы все равно ничего не поймем, значит строка вынутая из файла должна быть перекодирована из кодировки приставки в кодировку PC. Это тоже не проблема просто помимо кодов печатных символов нужно в нашей таблице указать какими кодами этот символ должен отображаться в кодировке PC. Поэтому в итоге таблица имеет структуру типа:
80=A 81=B 82=C 83=D 84=E 85=F
и так далее…
Причем ДО знака равенства пишется HEX код символа, а после знака равенства, каким ОДНИМ символом этот код выглядит на PC. Причем если вы вспомните Главу 1 (если конечно вы ее не пропустили), то скорее всего догадаетесь, что посмотрев на эту таблицу в шестнадцатиричном виде мы можем сделать и обратное преобразование.

Другими словами такая таблица может использоваться для перекодировки в обе стороны.
Вынув таким замысловатым образом текстовые последовательности из двоичного файла можно заняться их переводом в обычном текстовом редакторе. Подойдет даже WinWord, но сохранять перевод нужно в виде текстового файла (Только текст).
Остается только одна проблема, поскольку в файле такого формата нет указания на длину оригинальной строки, то лучше воспользоваться спец. редактором, который не даст вам вылезти за размеры оригинальной строки и соответственно не позволит забить непечатные символы, следующие за текстовой строкой.
А где же поинтеры? спросите вы – а это есть десятичное_смещение_в_двоичном_файле в файле вынутого текста, которое объяснит программе из какого места файла вынули эту строчку и даст возможность положить перевод в то же самое место.
Несколько общих замечаний:
- 1. Никто не мешает удлинить строку перевода, просто надо понимать, что вы рискуете забить своим текстом непечатные символы, и соответственно сделать игру неработоспособной.
- 2. Если перевод получается короче оригинала, нужно понимать, что если вы не нарастите свой укороченный перевод пробелами до оригинальной длины, то при выводе текста игра выведет еще и текст длиннее перевода. Игра ведь не знает, что строка стала короче и выведет то количество символов, которое было в оригинале. Если только в подсистеме вывода текста у игры нет зарезервированного специального кода, который говорит о том, что строка окончена.
- 3. Спец. символы, которые описаны в пункте 2 мы также можем описать как печатные и следовательно в своем текстовом редакторе сами расставлять концы строк.
- 4. При создании таблицы перекодировки нужно понимать, что одному коду всегда соответствует один символ (изображение) иначе программа перекодировки не сможет понять, как перекодировать переведенный текст. Иными словами таблица перекодировки должна быть обратимой.
- 5. Не переводите непонятные строки, скорее всего это исполняемые инструкции, просто оставьте их без изменений.
НЕОБРАТИМАЯ ТАБЛИЦА – это когда нельзя применив одну и ту же таблицу воссоздать первоначальный файл. Проверить обратимость очень просто, нужно ВЫНУТЬ текст из ROM’a затем НЕ изменяя полученный report.txt ВЕРНУТЬ его в ROM и потом сравнить (побайтно) полученные файлы, делать это например умеет WindowsCommander (выделить в одном окне входной файл, выделить в другом окне выходной файл а потом file -> compare by content) если входной и выходной файлы РАЗЛИЧАЮТСЯ то таблица НЕОБРАТИМА, то есть один тот же символ может перекодироваться в разные коды… такой таблицей пользоваться НЕСТОИТ поскольку она будет портить неоднозначные символы…
Собственно теоретическая часть на этом оканчивается, далее следуют суровые будни перевода 🙂
Все вышеописанные размышления, легли в основу программульки под названием PokePerevod, которая сейчас находится в состоянии бета тестирования. И далее я постараюсь показать как она облегчит жизнь переводчику интузазисту.
Глава 5 – Переводим Покемонов.
Сперва наперво требуется раздобыть образ американской или европейской версии ROM’a, В другой стране я посоветовал бы купить нормальный картридж, и устройство типа GB Transferer, которое позволит сделать backup картриджа на PC.
Предположим вы так и поступили, далее обзаведитесь описанными выше утилитами (они бесплатны), а PokePerevod даже раздается с исходным текстом, дабы знающие VisualBasic могли усовершенствовать эту программульку вусмерть :-).
Далее запускаем TileLayerPro и начинаем разглядывать ROM, видим примерно следующее:
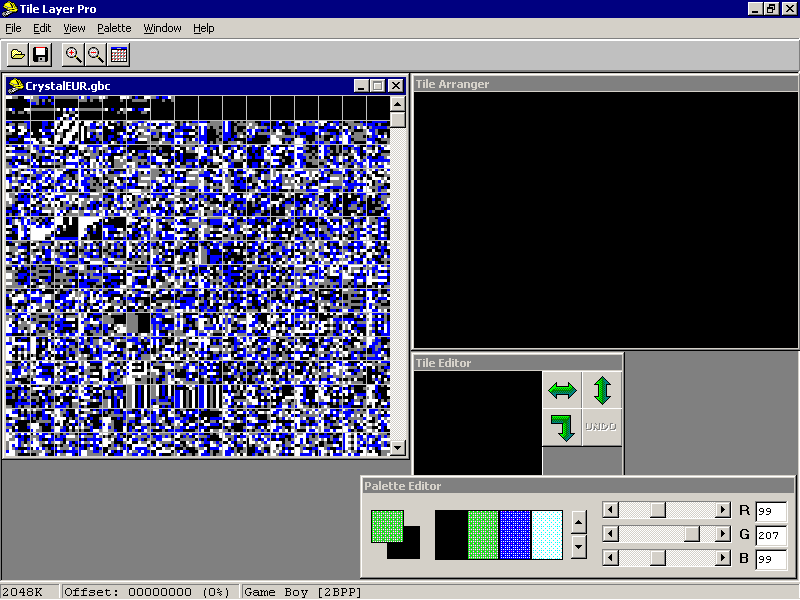
теперь переключимся в режим 1bpp View–>Format–>1BPP, что означает 1 Bit Per Point, в таком виде лежат шрифты в данном ROM’e. Как догадаться в каком формате лежат шрифты это отдельная песня и здесь не рассматривается. В худшем случае вам нужно пролистать/просмотреть весь ROM во всех вариантах :-).
Полистав некоторое время вы увидите экран типа этого:
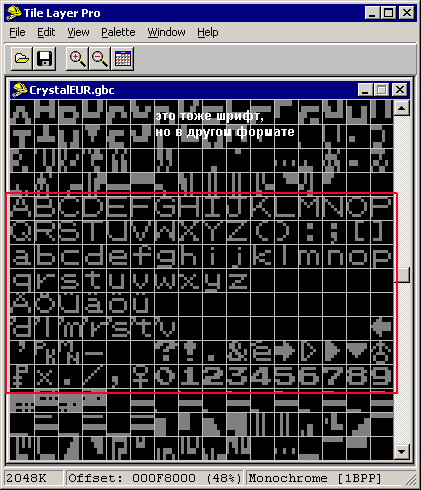
произойдет это примерно по смещению hex(F8200). Теперь мы знаем правую часть таблицы, то есть что сначала заглавные английские буквы, потом несколько символов “();:[]” потом маленькие английские и т.д. Подсчитав количество квадратиков можно узнать, что шрифт состоит из 128 символов, однако мы не знаем с какого кода начинается отсчет – соответствует ли код hex(00) коду заглавной “A” или нет 🙁 Если учесть опыт персоналок, то скорее всего нет, проведя ряд экспериментов (это возможно будет описано в будующих версиях этого руководства) мы наконец понимаем, что заглавной “A” имеет код hex(80). Ура половина дела сделана. В результате получим таблицу следующего вида: (это печатные английские символы)
80=A 81=B 82=C 83=D 84=E ...[пропущено] 99=Z 9A=( 9B=) 9C=: 9D=; 9E=[ 9F=] A0=a ...[пропущено] B7=x B8=y B9=z F6=0 F7=1 F8=2 F9=3 FA=4 FB=5 FC=6 FD=7 FE=8 FF=9
Таблица перекодировки готова, НО естественно это не все коды которые имеют соответствующие изображения, Полный вариант таблицы можно взять из дистрибутива PokePerevod.
Далее нам надо всунуть изображения символов кириллицы в этот шрифт (разобраться как это сделать остается на факультатив :-). В итоге у меня получилось нечто вроде:
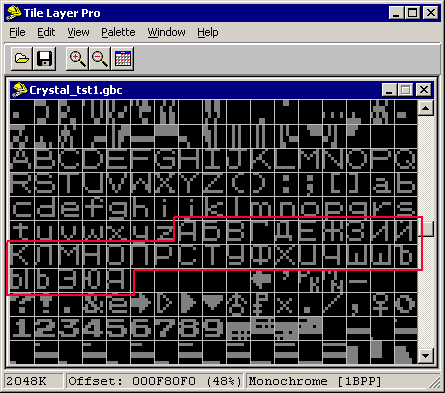
Обратите внимание я нарисовал русские буквы РЯДОМ, а не поверх английских символов, это значит, что игра будет по прежнему работать и показывать английский текст как прежде…
После урока рисования, начинается урок арифметики по вычислению кодов новоявленных русских букв 🙂 с соответствующим изменением таблицы перекодировки (ведь печатных символов у нас прибавилось). Обратите внимание еще на один момент, поскольку “свободного” места не так уж много, я довольствовался только заглавными русскими буквами. НЕ забудьте что переводить в этом случае можно будет ТОЛЬКО заглавными русскими…впрочем этого вполне достаточно.
Далее мы запускаем PokePerevod, загружаем ROM и таблицу и вынимаем текст в файл.
Файл будет большой и содержать будет много мусора типа:
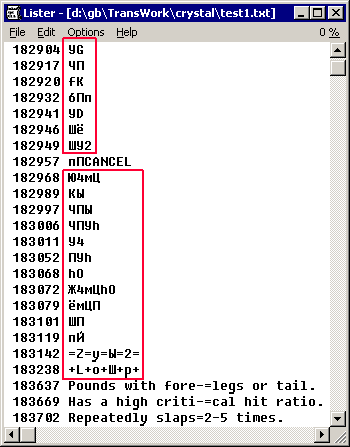
Это не должно нас останавливать, теперь это текстовый файл и можно заниматься переводом, правда я посоветовал бы открыть этот документ в notepad и удалить строки с непонятным текстом, тогда работать будет легче и быстрее.
Вынутый и почищенный файл перевода можно открывать в редакторе переводов в PokePerevod.(как работать с редактором перевода, надеюсь, когда нибудь напишет Толик 🙂
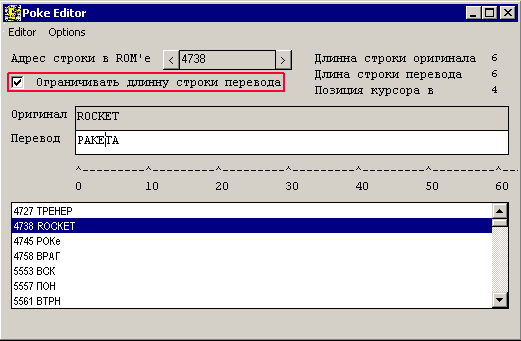
Самое главное редактор перевода не даст удлинять строку перевода (без специального на то разрешения), чем значительно ускорит работу. В том числе есть возможность “Найти и заменить” по всему переводу… 🙂 В общем, разберетесь…
Замечание, не пытайтесь сразу перевести весь текст, достаточно перевести пару слов, и вернув текст в ROM а потом запустив поправленный вариант ROM’a убедиться, что вы все сделали правильно. Возможно и даже наверняка выяснится, что можно добавить печатных символов в таблицу (на пример пробел :-)) для таких изысканий очень полезен GoldFinger, экран которого показан ниже:
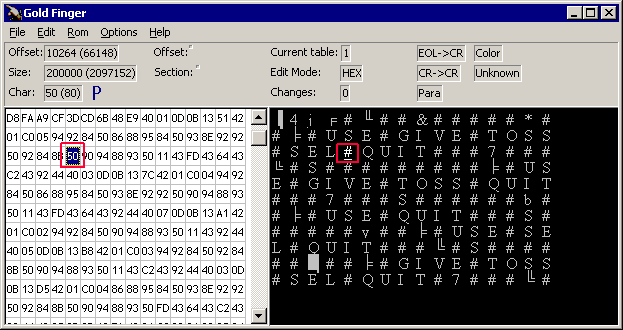
Формат таблиц описанный в данном руководстве (и используемый в PokePerevod) совместим с форматом таблиц для GoldFinger, но с одним исключением, GoldFinger при показе изображений символов использует досовскую кодировку (cp866) и следовательно, для того, чтобы увидеть, что мы там напереводили нужно открыть нашу виндоусовую таблицу (Windows-1251) в WordPad и сказать Save as –> MS DOS Format и такую вот таблицу подсунуть GoldFinger’у.

